题目:串联所有单词的子串
给定一个字符串s和一些长度相同的单词words。找出s中恰好可以由words中所有单词串联形成的子串的起始位置。
注意子串要与words中的单词完全匹配,中间不能有其他字符,但不需要考虑words中单词串联的顺序。
示例1:
输入:
s = "barfoothefoobarman",
words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
示例2:
输入:
s = "wordgoodgoodgoodbestword",
words = ["word","good","best","word"]
输出:[]
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words
解题思路
这题可以使用查找表,思路很简单,先来定义几个变量,方便下面更容易理解思路:
- len:每个单词的长度,根据题目已知
words中的每一个单词长度都是相等的 - wLen:
words中单词数量 - allLen:所有单词拼接后的长度
OK,定义完变量后来看看怎么用查找表实现:
- 首先对
s进行第一层循环,这层循环的目的就是水平扫描,以每一次循环i为起点,i的初始值为0,最大值为s.length-allLen- 这个最大值是怎么算出来的呢,如下图
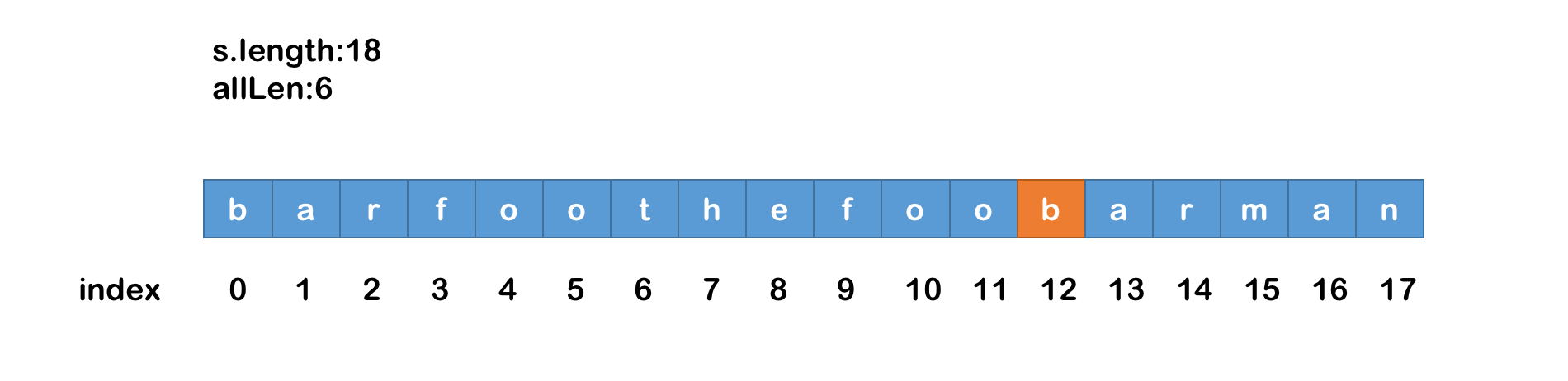
可以看到当index=12的时候从index开始到结尾字符串长度只剩下6位,如果index>12往后的字符串就无法构成长度为6的字符串,也就是allLen值,所以i只能去到s.length-allLen的位置
- 这个最大值是怎么算出来的呢,如下图
- 然后再看看从
i起往后的三个字符串是否在words数组中,如果不在那么也不需要进行第二层循环,如果存在则继续走下面的步骤 - 第二层循环就是进行查找表操作,为了方便书写代码可以把这层逻辑封装成一个函数,那么函数中的查找表逻辑如下:
- 建立一个映射
map把words数组中的单词全部记录,同时记录出现次数 - 然后根据从
s上以i为起点,allLen为终点截取字符串str,如下图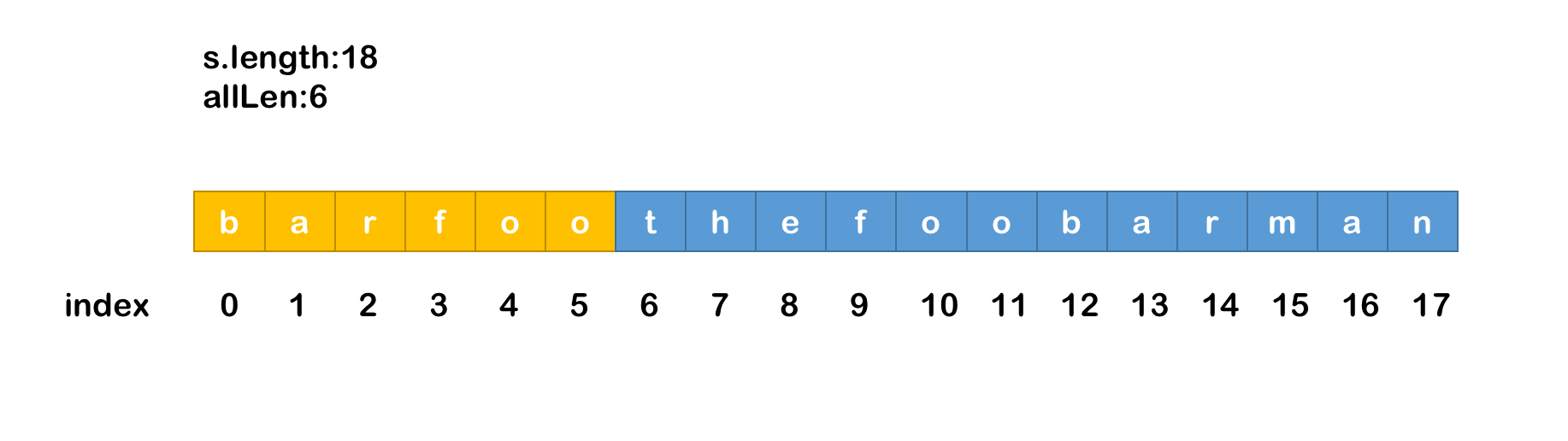
- 接下来对字符串进行第二层循环,每次循环截取一个长度为
len的子串substr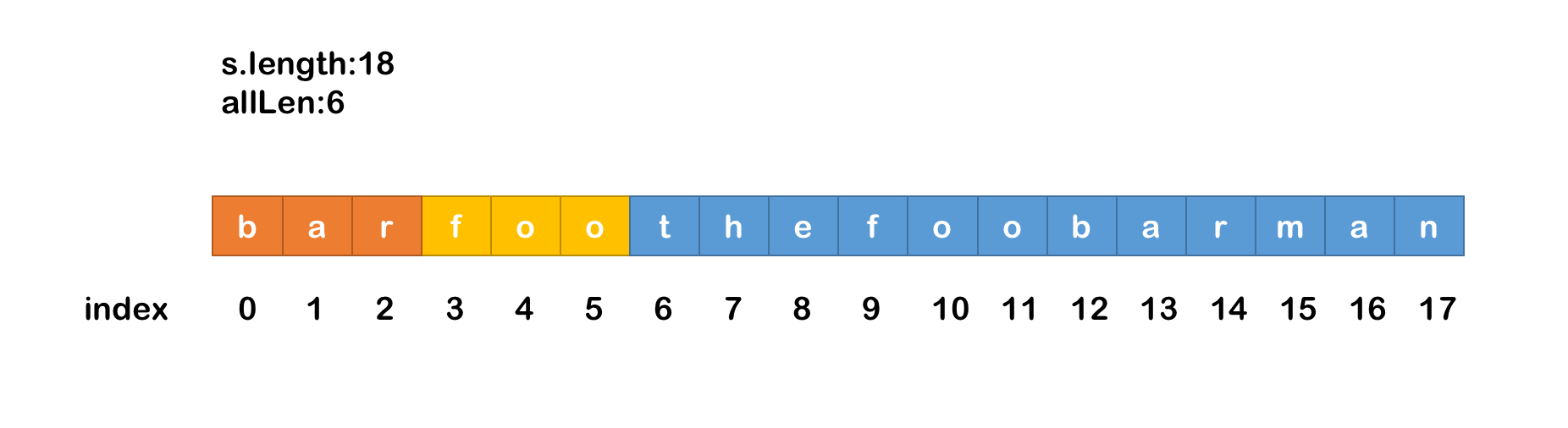
- 然后用
map检测substr的是否存在或者它的出现次数是否大于等于1,如果是则对出现值减1,否则证明str不是所有单词随机串联的结果,函数返回结果为false - 在
str遍历完后如果没有返回false则返回true,证明str符合随机串联要求
- 建立一个映射
- 当第一层循环接收到函数返回值为true后
i就是随机子串的起始位置
代码实现
let findSubstring = function (s, words) {
let res = [];
if (!words.length) return res;
let len = words[0].length,
wLen = words.length,
allLen = len * words.length;
for (let i = 0; i <= s.length - wLen * len; i++) {
let str = s.substring(i, i + len);
if (words.indexOf(str) !== -1 && helper(s, words, i, len, allLen)) {
res.push(i)
}
}
return res;
};
let helper = (s, words, i, len, allLen) => {
let map = new Map(),
str = s.substring(i, i + allLen);
for (word of words) {
map.set(word, (map.get(word) || 0) + 1);
}
for (let j = 0; j < allLen; j += len) {
let substr = str.substring(j, j + len);
if (map.get(substr) >= 1) {
map.set(substr, map.get(substr) - 1)
} else {
return false
}
}
return true
};